개인 기록용 글
코드는 다 여기저기서 가져온 거다
생성기 사이트에서 만드려고 했는데 글자수 제한이 있어서 파이썬으로 만들었다
들어가기 전에
워드 클라우드 = 단어 구름
이하 단어 구름으로 표기
여기서 얻은 데이터로 제목 단어 구름, 키워드 단어 구름을 만들어봤다
처음 해보는 거라 어떤 게 더 좋은지 몰라서 이것도 해보고 저것도 해봤다
그래서 여러 가지 방법을 다 글에 넣어보겠다
설치 및 준비
워드클라우드 설치
pip install wordcloud
터미널(cmd)에서 pip install wordcloud 가 안될 경우
Archived: Python Extension Packages for Windows – Christoph Gohlke (uci.edu)
이 링크로 가서 다운로드하여야 한다
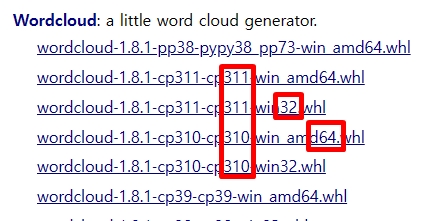
컴퓨터에 설치된 파이썬의 버전과 맞게 다운로드한다
(파이썬 3.10 버전이면 cp310으로 다운)
비트수도 맞춘다
(32 비트면 win32, 64 비트면 amd64)
그리고 다운로드 폴더에 가서 빈 공백에서 shift키 누른 채로 오른 클릭 – 여기서 명령창 열기 –
pip install wordcloud-어쩌고저쩌고. whl 입력한다
* 자기 컴퓨터 몇 비트인가 확인하는 법


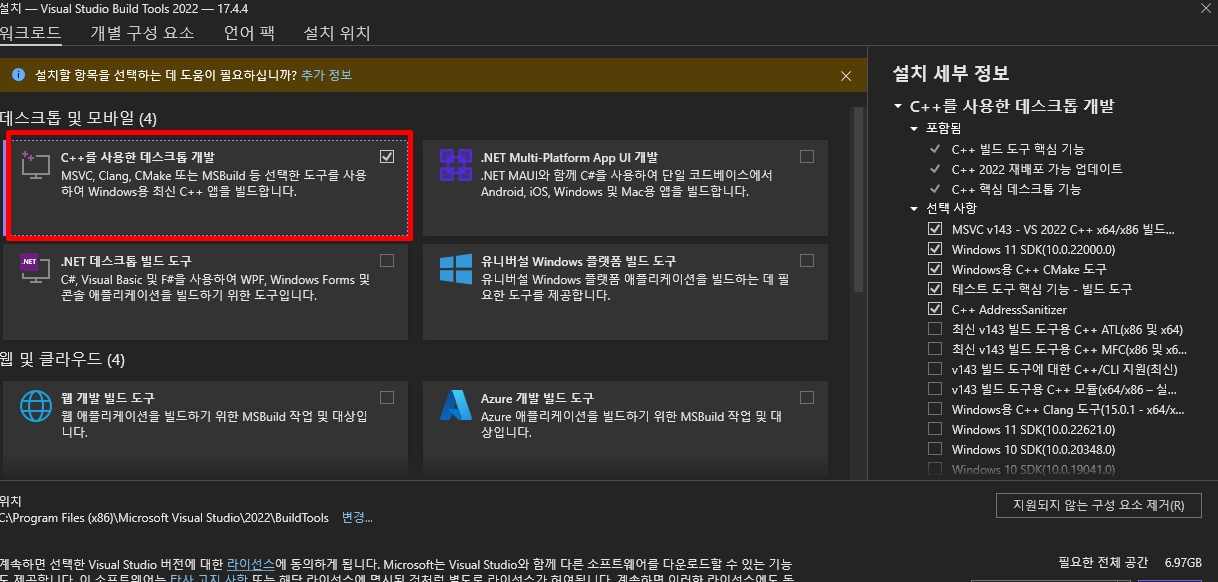
비주얼 C++ 설치
Microsoft C++ Build Tools – Visual Studio
여기서 Build tool 다운로드하고 실행한다
KoNLPy 설치
설치하기 — KoNLPy 0.6.0 documentation
1. 윈도우와 파이썬의 비트수가 같은지 확인
파이썬 설치 안되어있으면 아래 링크보고 파이썬 설치
윈도우 비트수 확인 법은 위에 썼다
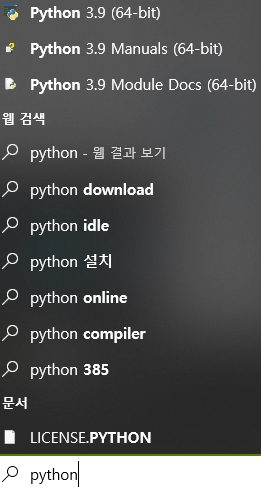
파이썬 비트수 확인: 컴퓨터 좌하단 검색창에 파이썬 치고 보니 이름 옆에 쓰여있었다
2. OS와 비트수가 일치하고, 버전이 1.7 이상인 자바가 설치되지 않다면 JDK를 설치
자바와 OS의 비트 수가 꼭 일치해야 한다.
3. 자바홈 설정
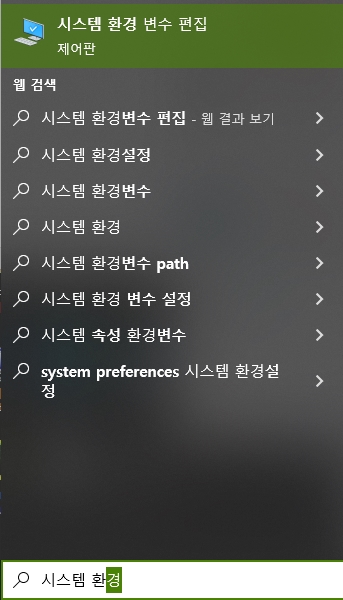
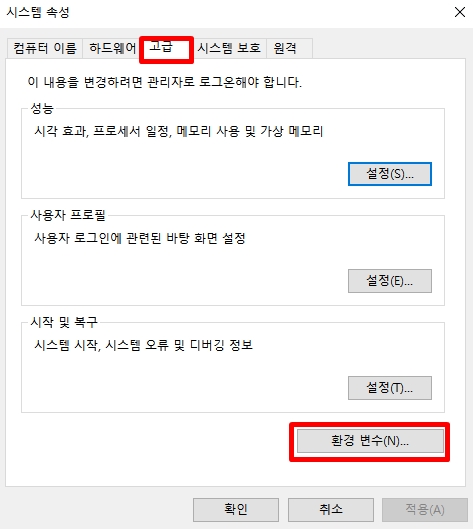
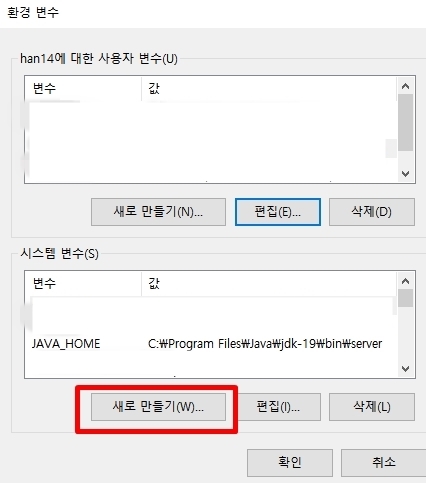

변수 이름: JAVA_HOME
변수 값: 설치된 폴더\bin\server (예: C:\Program Files\Java\jdk-19\bin\server)
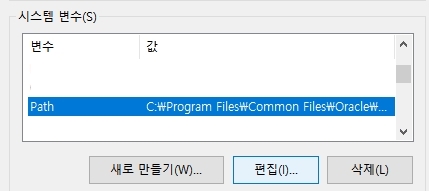

새로 만들기 – %JAVA_HOME%\bin\server\ 를 입력한다
4. OS의 비트 수와 일치하는 JPype1 (>=0.5.7) 를 설치
Archived: Python Extension Packages for Windows – Christoph Gohlke (uci.edu)
32비트는 win32, 64비트는 win-amd64 파일
whl 파일로 설치하는 경우에는 다음과 같이 cmd에서 pip을 업그레이드한다
pip install --upgrade pip pip install JPype1-0.5.7-cp27-none-win_amd64.whl
5. cmd에서 KoNLPy 설치
pip install konlpy
참고 페이지
워드 클라우드 공식 페이지
워드 클라우드 깃허브
GitHub – amueller/word_cloud: A little word cloud generator in Python
워드 클라우드 홈페이지
wordcloud.WordCloud — wordcloud 1.8.1 documentation (amueller.github.io)
Parameters 설명을 홈페이지에서 보면 좋다
Parameters 설명(번역기 돌림)
font_path: 문자열(string)
사용할 글꼴의 글꼴 경로(OTF 또는 TTF). Linux 시스템의 DroidSansMono 경로가 기본값입니다. 다른 OS를 사용 중이거나 이 글꼴이 없는 경우 이 경로를 조정해야 합니다.
width: 정수(int) (기본값=400)
캔버스의 폭.
height: 정수(int) (기본값=200)
캔버스의 높이.
prefer_horizontal: 부동 소수점(float) (기본값=0.90)
수직 피팅과 반대로 수평 피팅을 시도하는 시간의 비율입니다. prefer_horizontal < 1이면 알고리즘은 단어가 맞지 않으면 회전을 시도합니다. (현재 수직 단어만 가져오는 기본 제공 방법은 없습니다.)
mask: nd-array 또는 없음(기본값=없음)
None이 아니면 단어를 그릴 위치에 대한 바이너리 마스크를 제공합니다. 마스크가 None이 아니면 너비와 높이가 무시되고 마스크 모양이 대신 사용됩니다. 모든 흰색(#FF 또는 #FFFFFF) 항목은 “마스크 아웃”된 것으로 간주되며 다른 항목은 자유롭게 그릴 수 있습니다.
contour_width: 부동 소수점(float)(기본값=0)
마스크가 None이 아니고 contour_width > 0이면 마스크 윤곽선을 그립니다.
contour_color: 색상 값(기본값=”검은색”)
마스크 윤곽 색상.
scale: 부동 소수점(float) (기본값=1)
계산과 그리기 간의 크기 조정. 큰 단어 구름 이미지의 경우 더 큰 캔버스 크기 대신 배율을 사용하는 것이 훨씬 빠르지만 단어가 더 조잡하게 맞을 수 있습니다.
min_font_size: 정수(int) (기본값=4)
사용할 가장 작은 글꼴 크기. 이 크기에 더 이상 공간이 없으면 중지됩니다.
font_step: 정수(int) (기본값=1)
글꼴의 단계 크기입니다. font_step > 1은 계산 속도를 높일 수 있지만 더 적합하지 않습니다.
max_words: 숫자(기본값=200)
최대 단어 수입니다.
stopwords: 문자열(string) 세트 또는 없음
제거할 단어입니다. None이면 내장된 STOPWORDS 목록이 사용됩니다. generate_from_frequencies를 사용하는 경우 무시됩니다.
background_color: 색상 값(기본값=”검은색”)
단어 구름 이미지의 배경색입니다.
max_font_size: 정수(int) 또는 없음(기본값=없음)
가장 큰 단어의 최대 글꼴 크기. None이면 이미지 높이가 사용됩니다.
mode: 문자열(string)(기본값=”RGB”)
모드가 “RGBA”이고 background_color가 None이면 투명한 배경이 생성됩니다.
relative_scaling: 부동 소수점(float) (기본값=’auto’)
글꼴 크기에 대한 상대적인 단어 빈도의 중요성. relative_scaling=0이면 단어 순위만 고려됩니다. relative_scaling=1이면 빈도가 두 배인 단어는 크기가 두 배가 됩니다. 순위뿐만 아니라 단어 빈도를 고려하려면 0.5 정도의 relative_scaling이 좋은 경우가 많습니다. ‘자동’인 경우 반복이 참이 아니면 0.5로 설정되며 이 경우 0으로 설정됩니다.
color_func: 호출 가능(callable), 기본값=없음
각 단어에 대한 PIL 색상을 반환하는 word, font_size, position, orientation, font_path, random_state 매개변수로 호출 가능합니다. “컬러맵”을 덮어씁니다. 대신 matplotlib 색상표를 지정하려면 색상표를 참조하세요. 단일 색상으로 단어 구름을 만들려면 를 사용합니다. 단일 색상은 RGB 코드를 사용하여 지정할 수도 있습니다. 예를 들어 색상을 색상을 빨간색으로 설정합니다. color_func=lambda *args, **kwargs: “white” color_func=lambda *args, **kwargs: (255,0,0)
regexp: 문자열(string) 또는 없음(선택 사항)
입력 텍스트를 process_text의 토큰으로 분할하는 정규식입니다. None이 지정되면 가 사용됩니다. generate_from_frequencies를 사용하는 경우 무시됨 r”\w[\w’]+”
collocations: bool, 기본값=True
두 단어의 연어(바이그램)를 포함할지 여부입니다. generate_from_frequencies를 사용하는 경우 무시됩니다.
colormap: 문자열(string) 또는 matplotlib 컬러맵, 기본값=”viridis”
Matplotlib colormap은 각 단어에 대해 무작위로 색상을 그립니다. “color_func”가 지정된 경우 무시됩니다.
normalize_plurals: bool, 기본값=True
단어에서 후행 ‘s’를 제거할지 여부입니다. True이고 후행 ‘s’가 있거나 없는 단어가 나타나면 후행 ‘s’가 있는 단어가 제거되고 단어가 ‘ss’로 끝나지 않는 한 후행 ‘s’가 없는 버전에 개수가 추가됩니다. generate_from_frequencies를 사용하는 경우 무시됩니다.
repeat: bool, 기본값=False
max_words 또는 min_font_size에 도달할 때까지 단어와 구(phrase)를 반복할지 여부입니다.
include_numbers: bool, 기본값=False
구(phrase)로 숫자를 포함할지 여부입니다.
min_word_length: 정수(int), 기본값=0
단어가 포함되어야 하는 최소 문자 수입니다.
collocation_threshold: 정수(int), 기본값=30
바이그램은 바이그램으로 계산되려면 더닝 가능도 연어 점수(Dunning likelihood collocation score)가 이 매개변수보다 더 커야 합니다. 기본값 30은 임의적입니다.
컬러맵
아래 주소를 참고하면 된다
Choosing Colormaps in Matplotlib — Matplotlib 3.6.3 documentation
워드 클라우드 만들기
기본
의외로 간단한 방법은 찾기가 더 힘들더라
거의 다들 형태소 나눈 다음에 단어 구름 만들던데
리디 키워드는 그렇게 만들면 안 되고 키워드 형태 그대로 만들어줘야 한다
그래서 기본적인 방법을 가져왔다
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# open으로 txt파일을 열고 read()를 이용하여 utf-8 읽음
text = open('test.txt', encoding='utf-8').read()
# 단어 구름을 만듦
# font_path= 폰트 파일 경로. py 파일과 같은 폴더에 있으면 아래와 같이 써도 되지만 아니면 C:/Windows/Fonts/RIDIBatang.ttf 이런식으로 위치를 써야 함
wc = WordCloud(font_path='RIDIBatang.ttf', width=400, height=400, scale=1.5, background_color="white", colormap="tab20b", max_font_size=250, collocations=False).generate(text)
plt.figure()
# 단어 구름 보여줌. bilinear = 부드럽게.
plt.imshow(wc, interpolation='bilinear')
# 파일로 저장
wc.to_file('wordcloud_test1.png')
# 중복 단어 나오는 거 'collocations=False'로 제거함* 파이참에 자동 줄 바꿈(소프트 랩) 있음 그거 쓸 것
collocations=False 안 넣었을 때는 이미지에서 중복 단어가 보였다
빈도수 세기 + 이미지 마스킹
# 리디 키워드 그냥 생긴대로 빈도수 집계하고, 그걸 바탕으로 워드 클라우드 만듦
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# open으로 txt파일을 열고 read()를 이용하여 utf-8 읽음
text = open('test.txt', encoding='utf-8').read()
# 키워드 빈도수 세기
from collections import Counter
with open(r'test.txt', encoding='UTF-8') as f:
p = Counter(f.read().split())
# 키워드 빈도수 파일로 저장하고 싶으면 아래 세 줄 '#'빼기
#import sys
#sys.stdout = open('키워드빈도수.txt', 'w')
#print(p)
# 이미지는 py 파일과 같은 폴더에 넣음
masking_image = np.array(Image.open("heart.png"))
# 윤곽선 넣기 싫으면 뺄 것 -> contour_width=윤곽선 두께, contour_color=윤곽선 색
wc = WordCloud(font_path='RIDIBatang.ttf', width=400, height=400, scale=1.5, contour_width=0.01, contour_color="#EFEFEF", background_color="white", colormap="copper", max_font_size=250, mask=masking_image).generate(text)
wc = wc.generate_from_frequencies(p)
plt.figure()
plt.imshow(wc, interpolation='bilinear')
wc.to_file('wordcloud_test.png')
# 중복 단어 나오는 거 빈도수 세서 제거함이미지 마스킹
: 사진이 있으면 흰 부분에는 글씨가 안 써지고 색 있는 부분에만 글씨가 써진다
화질이 좋을수록 결과물이 깔끔하게 나온다
특히 윤곽선을 그릴 거라면 png로 작업하는 것을 추천 (투명 배경은 안된다)
jpg로는 지저분하게 그려진다

jpg로 만들면 위와 같이 윤곽선 주위에 네모네모들이 있다
단어들이 공간에 꽉 안차면 글자 최대 개수(max_words)를 늘리거나 글자 최대 크기(max_font_size)를 키워주면 된다
komoran 형태소 분석 이용
제목으로 만들어보니 형태소 분석으로 정리하는 게 필요하겠다 싶어서 가져와 봄
from wordcloud import WordCloud
from konlpy.tag import Komoran
from collections import Counter
import numpy as np
from PIL import Image
# open으로 txt파일을 열고 read()를 이용하여 utf-8 읽음
text = open('title_test.txt', encoding='utf-8').read()
# Komoran 함수를 이용해 형태소 분석
komoran = Komoran()
line =[]
line = komoran.pos(text)
n_v =[]
# 명사와 동사 만 n_v에 넣어줌
for word, tag in line:
if tag in ['NNG','NNP','VV','VA']:
n_v.append(word)
#제외할 단어 추가(를과 의를 삭제함)
stop_words = "를 의" #추가할 때 띄어쓰기로 추가해주기
stop_words = set(stop_words.split(' '))
# 불용어를 제외한 단어만 남기기
n_v = [word for word in n_v if not word in stop_words]
#가장 많이 나온 단어 200개 저장 (원하는대로 숫자 바꾸기)
counts = Counter(n_v)
tags = counts.most_common(200)
print(tags)
# WordCloud를 생성한다.
# 마스크 이미지로
img = Image.open('heart.png')
imgArray = np.array(img) # 이미지의 각 셀을 수치로 변환
# 단어 200개 이상 넣고 싶으면 괄호 안에 max_words= 넣고 200개 이상 숫자 써줘야 함
wc = WordCloud(font_path='RIDIBatang.ttf', width=400, height=400, background_color='white',scale=1.5, mask=imgArray, colormap='tab20b', contour_width=0.01, contour_color="#EFEFEF", max_font_size=300)
cloud = wc.generate_from_frequencies(dict(tags))
import matplotlib.pyplot as plt
plt.figure(figsize=(15,15))
plt.imshow(cloud)
plt.axis('off')
# 저장
plt.savefig('fontcloud.png', bbox_inches='tight')figsize는 15, scale은 1.5 이상은 되어야 화질이 좋은 것 같다
okt 형태소 분석 (명사만 추출)
다른 형태소 분석 방법은 어떤지 궁금해서 시도해 봄
okt 형태소 분석기 = (구) 트위터 형태소 분석기
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
from konlpy.tag import Okt
from PIL import Image
import numpy as np
with open('title_test.txt', 'r', encoding='utf-8') as f:
text = f.read()
okt = Okt()
nouns = okt.nouns(text) # 명사만 추출
c = Counter(nouns) # 위에서 얻은 words를 처리하여 단어별 빈도수 형태의 딕셔너리 데이터를 구함
masking_image = np.array(Image.open("heart.png"))
wc = WordCloud(font_path='RIDIBatang.ttf', width=400, height=400, scale=2.0, max_font_size=250, contour_width=0.1, contour_color="#ECECEC", colormap="tab20", background_color="white", mask=masking_image)
gen = wc.generate_from_frequencies(c)
plt.figure(figsize=(15,15))
plt.imshow(gen)
#plt.axis("off")
#plt.tight_layout(pad=0)
wc.to_file('mask_워드클라우드.png')okt 형태소 분석 (다른 형태소도 추출)
komoran에서 용언 ‘+ 다’로 원형 만들기 시도하다가 안 됐다
그런데 검색 중 okt에는 원형 만들어주는 기능이 있다고 해서 해봤다
그리고 다른 형태소들도 넣어보고 싶어서 방법을 찾았다
from konlpy.tag import Okt
from collections import Counter # 개수 일종의 dic 형태로 세기
from wordcloud import WordCloud # 워드 클라우드 이미지 만들기
import matplotlib.pyplot as plt # 만들어진 이미지 보이기
import numpy as np
from PIL import Image
sample_text = open('title_test.txt', encoding='utf-8').read()
okt = Okt() # Okt 품사 태깅 클래스 활용
line =[]
# okt.pos=형태소 분석, norm=True: 품사 태깅, stem=True: 원형으로 바꿈
line = okt.pos(sample_text, norm=True, stem=True)
n_un =[]
# 원하는 품사만 n_un에 넣어주기 (명사, 동사, 형용사, 부사, 감탄사, 알파멧, 숫자, 외국어, 관형사, 미등록)
for word, tag in line:
if tag in ['Noun','Verb','Adjective','Adverb','Exclamation','Alpha','Number','Foreign','Determiner','Unknown']:
n_un.append(word)
#가장 많이 나온 단어 200개 저장 (원하는대로 숫자 바꾸기)
counts = Counter(n_un)
tags = counts.most_common(200)
print(tags)
masking_image = np.array(Image.open("heart.png"))
# 단어 200개 이상 넣고 싶으면 괄호 안에 max_words= 넣고 200개 이상 숫자 써줘야 함
wordcloud = WordCloud(font_path="RIDIBatang.ttf",
max_font_size=300, background_color="white", colormap="tab20",
width=400, height=400, scale=2.0, contour_width=0.1, contour_color="#ECECEC",
mask=masking_image)
# stopwords : 리스트 형태로 된 불용어(인터넷 검색 시 검색 용어로 사용하지 않는 단어) 설정
# stopwords 만들때 Tip
# stopwords = "아 이 우 에 오"
# stopwrods = set(stopwords.split(" ")) # set을 활용해 { } 형태로 바꾸기
result = wordcloud.generate_from_frequencies(dict(tags)) # 워드클라우드 이미지 만들기
plt.figure(figsize=(15, 15)) # 크기 조정이 이미지 그리기 전에 있으면 안됨
plt.imshow(result) # 이미지 보이기
plt.axis('off') # x, y축 없애기
plt.tight_layout() # 이미지 크기 딱 맞게 조정
#plt.show() # 이미지 보이기
plt.savefig("first_word.png") # first_word.png 로 이미지 저장
result.to_file('first_word.png')형태소 품사 태그표
https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit#gid=0
모듈의 상세사항은 아래 페이지의 API 문서 보기
tag Package — KoNLPy 0.6.0 documentation
이거 다 만들고 나서 글자수 많아도 예쁘게 잘 만들어주는 사이트 찾아서 좀 허탈했다
그런데 다시 생각해 보니 괜찮았다
그 사이트에서는 키워드 원래 형태로 안 나오더라
그리고 파이썬으로 하면 내 마음대로 형태소 취사선택해서 만들 수 있다