리디 키워드 크롤링한 방법. 리디의 키워드 검색 페이지에서 크롤링했다.
개인 기록용
덕질에 쓰려고 처음 해보는 거라 미숙함
다른 사람이 보기엔 누더기 같을 수 있음
기본적으로 이 페이지 참고함
코딩을 몰라도 쉽게 만드는 데이터수집기 – 쉽게 따라 하는 데이터수집기 만들기 (coalastudy.com)
근데 옛날에 썼나 봐
지금이랑 안 맞는 거 있음ㅇㅇ
키워드 검색 페이지 = 동적 페이지
동적 페이지는 셀레니움 쓰라고 함
리디 키워드 크롤링 방법
기존 설치 프로그램
파이썬
엑셀 읽을 수 있는 프로그램
크롬 브라우저
파이썬 다운로드 링크
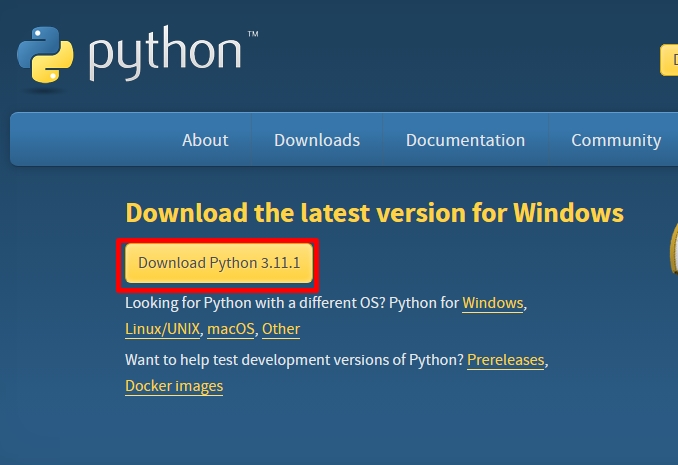
다운로드 받고 설치
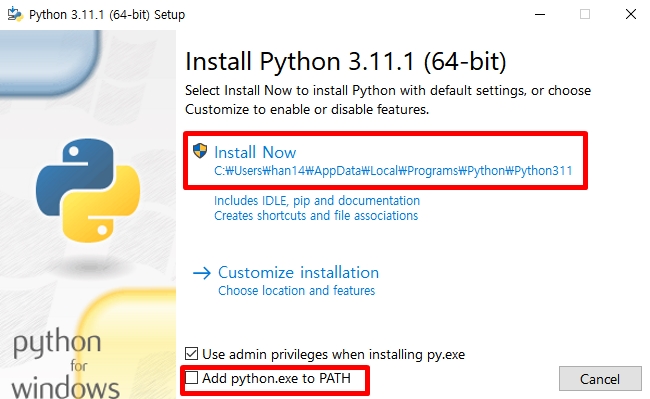
아래 체크박스 체크하고 install now 누름
엑셀 없으면 엑셀 대체 프로그램 설치하거나
리브레오피스 안정 버전 | 리브레오피스 – 한국어 페이지 (libreoffice.org)
구글 시트, 엑셀 뷰어 등을 이용함
크롬 다운로드 링크
설치한 것
pycharm community edition
webdriver for chrome
selenium
Download PyCharm: Python IDE for Professional Developers by JetBrains
파이참 다운로드 링크
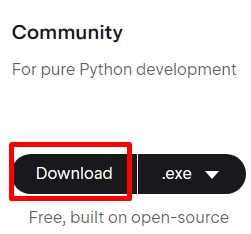
다운로드 받고 설치
쭉쭉 next 누르다가 아래 화면 나오면 정지
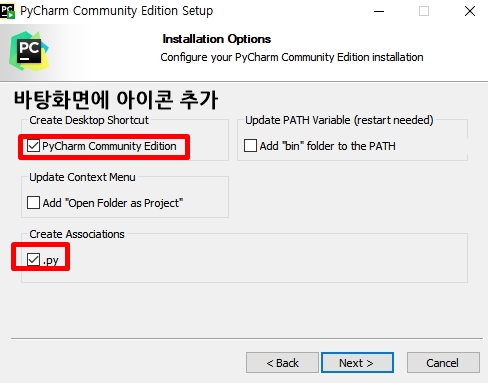
체크한 부분 누르고 설치
ChromeDriver – WebDriver for Chrome – Downloads (chromium.org)
webdriver for chrome 다운로드 링크
크롬브라우저에서 도움말-크롬 정보에서 버전을 보고 그에 맞게 설치
압축파일을 풀면 나오는 파일을 파이썬을 돌릴 폴더(프로젝트 폴더)에 옮김
셀레니움은 커맨드 창에서 pip install selenium하면 됨
선택자
컨테이너 div.RSGBookMetadata
제목 a.RSGBookMetadata_Title
저자 a.RSGBookMetadata_Authors_Item
평점(rate) span.StarRate_Bar (숫자만)
별점 수 span.StarRate_ParticipantCount
권 수 div.RSGBookMetadata_SeriesCount (숫자만 뽑기)
1권 가격 span.RSGBookMetadata_Price_CurrentPrice museoSans
출판사 div.RSGBookMetadata_Publisher
키워드 리스트 ul.KeywordLists
1권 가격이랑 전권 가격이랑 선택자 같던데 어떻게 해야 하나 헤매다가
권 수 나오니까 알아서 판단하겠지 뭐 하고 일단 넘어감
* selector 복사: 선택자 알아내기에 좋음
데이터 수집
설치한 pycharm을 실행 – New project
pycharm에 쓴다
맞는 코드 찾기전 발생한 오류 )
맨 처음에는 BeautifulSoup 써서 해보려고 했음
그랬더니 뭐가 안 나와
알고 보니 동적 페이지라서 안되었던 것
페이지 소스를 확인해 보니 텅 비어있었다
베스트셀러 페이지에서 페이지 당 작품 10개씩만 내놓는 것도 마찬가지 이유
# 데이터 수집하기 (선택한 키워드 "별점 천개 이상", "단행본")
# 여러 페이지에서 작품 제목, 작가, 평점 등 모음
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["제목", "저자", "평점", "별점 수", "가격", "출판사", "권 수", "키워드"])맞는 코드 찾기전 발생한 오류 )
맨 위 참고 페이지 했는데 오류가 나옴
executable_path has been deprecated, please pass in a Service object
셀레니움이 4.0에 들어가면서 바뀌었대
그래서 버전에 맞게 코드 수정하고
파이참 밑에 있는 terminal 누르고 pip insall webdriver_manager로 설치함
맞는 코드 찾기전 발생한 오류 )
name time is not defined
import time을 앞에 안 써줘서 생긴 오류
->
하라는 대로 한 거 같은데 import time이 활성화 안됨
그래서 이거 되는 거 같은 남의 코드 가져옴
그랬더니 겨우겨우 됐네
그리고 나중에 알았는데 앞에 time 쓰고 뒤에 그거 활용하는 게 없으면 회색이 되나 봐
맞는 코드 찾기전 발생한 오류 )
openpyxl이 없다고 오류
그래서 파이참 밑에 있는 terminal 누르고 pip insall openpyxl로 설치함
chrome_driver = ChromeDriverManager().install()
service = Service(chrome_driver)
driver = webdriver.Chrome(service = service)for p in range(1, 50):
URL = ("https://ridibooks.com/keyword-finder/romance?order=recent&page=" + str(p) + "&set_id=1&adult_exclude=n&tag_ids%5B0%5D=3127&tag_ids%5B1%5D=3428")
driver.get(URL)
time.sleep(3)order=는 정렬 기준
order=recent : 최신순
order=selling : 인기순
order=review_cnt : 리뷰 많은 순
page=숫자 : 몇 페이지인지
그다음 &부터 끝까지는 태그 선택에 따라 달라짐
내가 선택한 “별점 천 개 이상”+”단행본”에는 페이지가 49개쯤 있어서 페이지 숫자를 1부터 50까지 늘어나게 함
from selenium.webdriver.common.by import By
# 컨테이너(책정보) 수
books = driver.find_elements(By.CSS_SELECTOR, "div.RSGBookMetadata")
for book in books:
# 세부 데이터 수집
# 제목
title = book.find_element(By.CSS_SELECTOR, "a.RSGBookMetadata_Title").text
# 저자
author = book.find_element(By.CSS_SELECTOR, "a.RSGBookMetadata_Authors_Item").text
# 평점
rate = book.find_element(By.CSS_SELECTOR, "span.StarRate_Bar").text
# 별점 수
Count = book.find_element(By.CSS_SELECTOR, "span.StarRate_ParticipantCount").text
# 가격 (한 권 가격)
price = book.find_element(By.CSS_SELECTOR, "span.RSGBookMetadata_Price_CurrentPrice.museoSans").text
# 출판사
Publisher = book.find_element(By.CSS_SELECTOR, "div.RSGBookMetadata_Publisher").text맞는 코드 찾기전 발생한 오류 )
AttributeError: ‘WebDriver’ object has no attribute ‘find_elements_by_css_selector’
코드가 바뀌었대..
그래서 검색결과가 알려준 대로 webdriver_manager를 설치하고 코드를 바꿔줬다
옛날엔 find_element_by_css_selector( 이렇게 썼는데
이제는 find_element(By.CSS_SELECTOR, 이렇게 쓴다는 거
맞는 코드 찾기전 발생한 오류 )
WebElement’ object is not iterable
컨테이너에 넣는 Element는 복수를 써야 한대
여러 개니까
books = driver.find_elements(
그래서 s를 집어넣어 줌
# 키워드 리스트
keyword_list = book.find_element(By.CSS_SELECTOR, 'ul.KeywordLists').text맞는 코드 찾기전 발생한 오류 )
keyword = book.find_elements(By.CSS_SELECTOR, ‘button.Keyword_ToggleButton’).text 넣었더니
list object has no attribute ‘text’ 뜸
리스트는 text 메소드 안된대
그래서 인터넷 ‘인스타그램 해시태그 크롤링’ 찾아서 이것저것 따라 해 봤는데 다 실패함
그냥 키워드 리스트 한꺼번에 가져오는 걸로 함
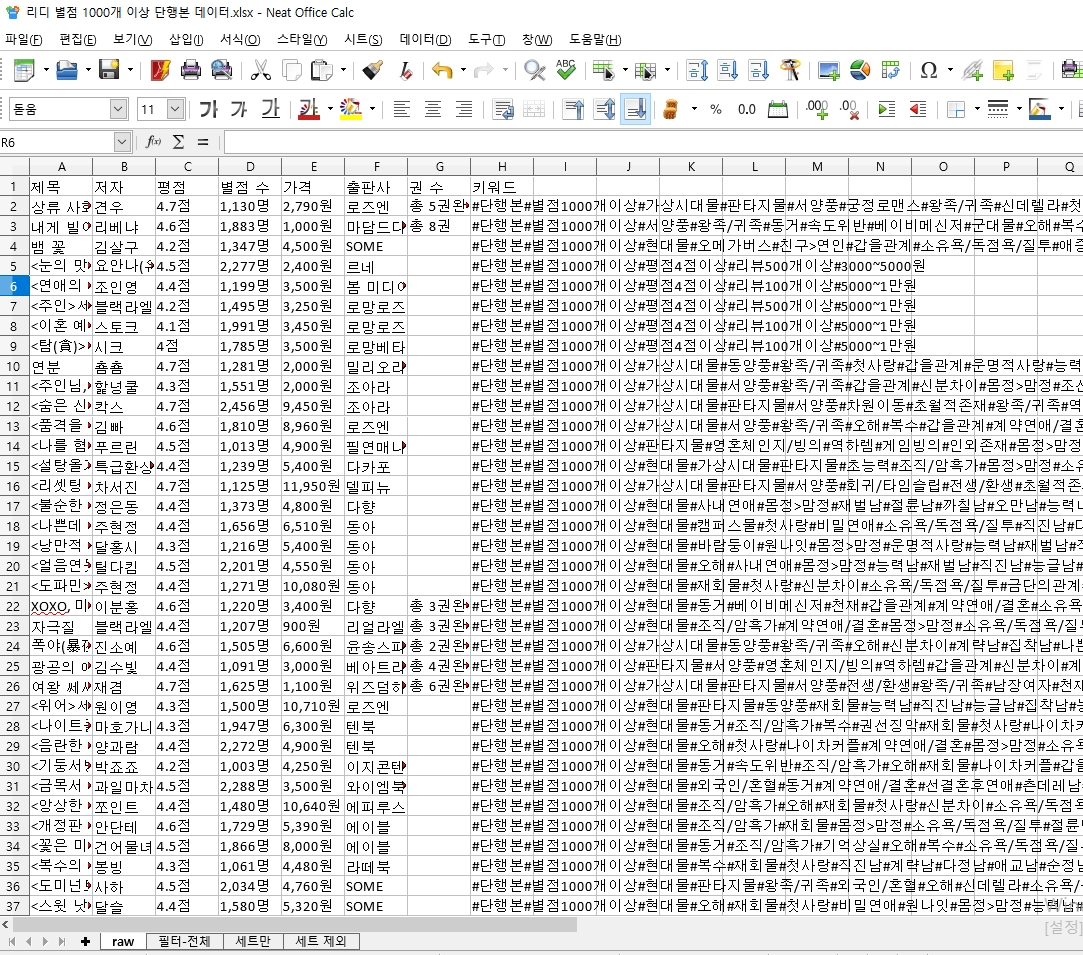
그러면 “#판타지물#조신남#MARK-DOWN#단행본” 이런 식으로 다 붙여져 나옴
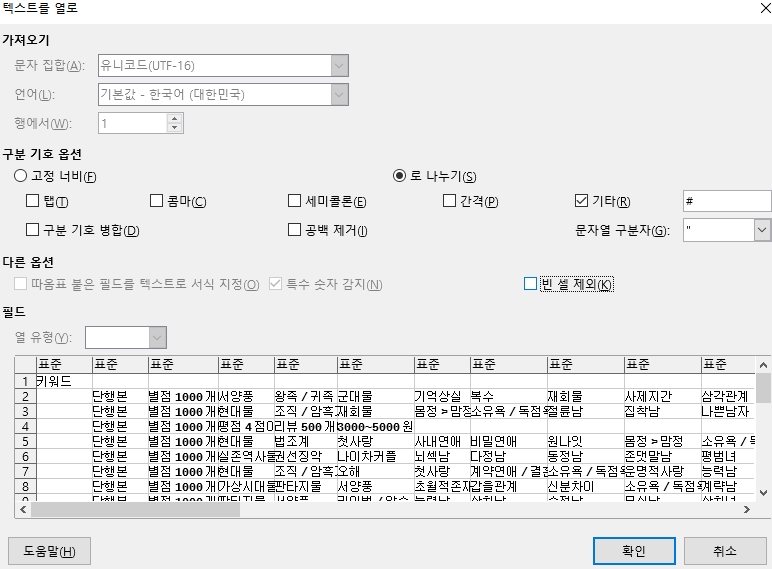
‘#’를 기준으로 분리 가능함
key_result = keyword_list.split(‘#’)
위와 같이 split 하면 [”, ‘단행본’, ‘별점1000개이상’, ‘평점4점이상’, ‘리뷰500개이상’, ‘3000~5000원’] 이렇게 나옴
maxsplit=-1은 제한 없음. 안 써도 결과는 같음
이렇게 하면 엑셀에 저장 안 됨
그래서 엑셀에서 ‘셀 > 데이터 > 텍스트 나누기’ 선택해서 분리하기로 함
# 권 수 값이 없으면 빈 칸을 넣음
try:
volume = book.find_element(By.CSS_SELECTOR, 'div.RSGBookMetadata_SeriesCount').text
except Exception as error:
volume = " "맞는 코드 찾기전 발생한 오류)
try except를 안 썼을 때는 오류가 났음
AttributeError: ‘NoneType’ object has no attribute ‘text’
단권 작품이나 세트 작품에는 ‘권 수’ 값이 없어 오류가 났던 것
그래서 일단 하란대로 해보고 에러가 나면 권 수에 빈칸을 넣으라고 씀
맞는 코드 찾기전 발생한 오류)
unindent does not match any outer indentation level
들여 쓰기가 안 맞아서 생기는 오류
탭 키로 잘 맞춰주자
print(title, author, rate, Count, price, Publisher, volume, keyword_list)
sheet.append([title, author, rate, Count, price, Publisher, volume, keyword_list])
wb.save("ridibooks+keyword.xlsx")
driver.close()* 저장할 때마다 엑셀 파일명 바꾸기
엑셀 파일은 py 파일이 있는 폴더에 있다
해당 py 파일 오른 클릭 – open in explorer 누른다
엑셀
* 키워드 다 모으고 워드 클라우드 생성기 사용하면 재밌을 거 같음
다음글